Row_number in SQL is a window function which basically generates a unique positive integer number against a every rows of a table. It is widely used in SQL irrespective of type of databases, whether it is a SQL server, Mysql, PostgreSQL etc etc.
Table of Contents
Use Case of ROW_NUMBER :
Whenever you need to get a unique identity of a row you can use this window function to get a row number and based on that row number you can perform your task. It generates on run time and will not be saved in your table.
In this post I am going to give you the ultimate 10 ways to remove duplicates in SQL in two scenario along with a youtube video in hindi where I have executed all the queries.
Please open this in desktop mode for better experience because code panel will be viewed better in desktop mode.
I have shown the methods how to delete all duplicate record except one record from the table and except the solution no. 5 & 3( scenario 2 ) we can use all the methods to delete duplicates in production environment as well.
Table of Contents
What is Deduplication in SQL?
Deduplication basically refers to a method of eliminating the duplicate data from a dataset or table. It is very important task to do so especially for any task from where you going to get some insights.
Duplicate data from a table can change the whole theme. There are many ways to remove redundant data from a table or data set. I have explained the 10 ways to remove duplicates in SQL in two scenario.
How Duplicate Happens
Duplicates can be entered in a table in many ways like each and every column will be duplicated, I mean the whole row can be duplicated or there may have a column which will unique but rest columns data will be duplicate.
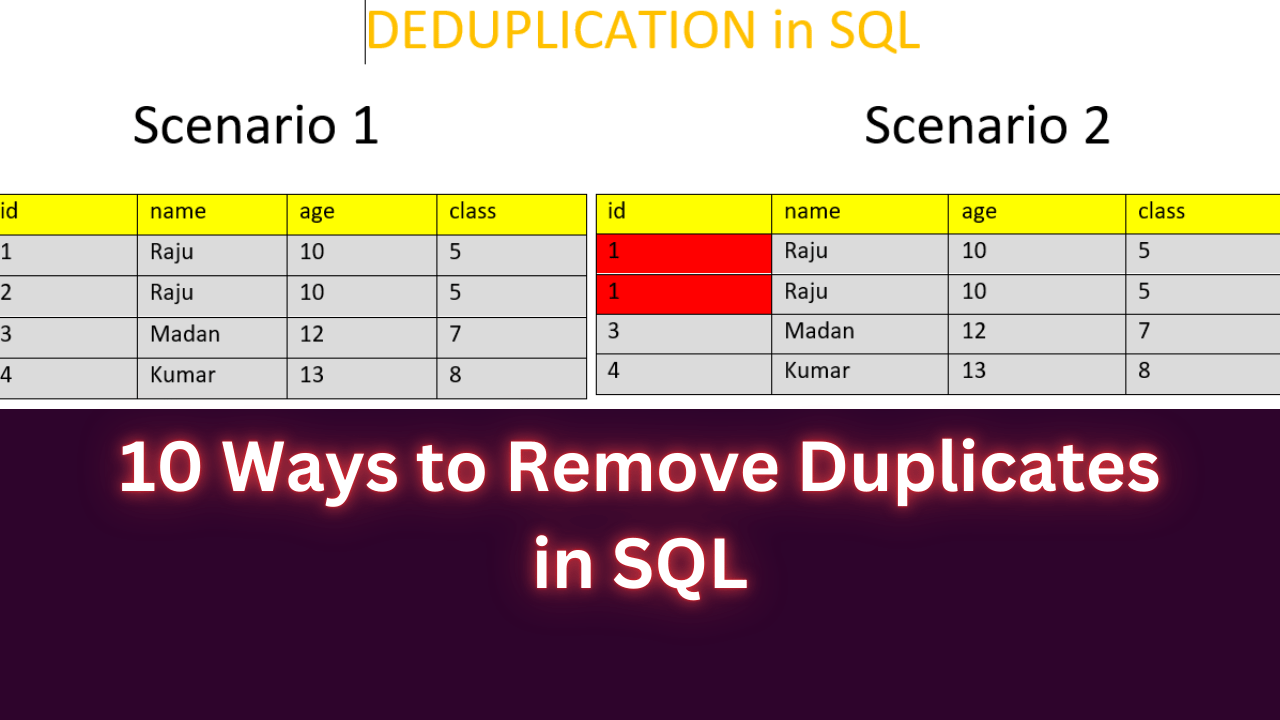
Scenario 1 :
At least one column having unique record. Here in my scenario a table called “students” having columns id, name,age,class and the column id is unique.
Sol 1 : Using unique identifier
delete from students
where id in(
select max(id) from students group by
name,age having count(*)>1)
Sol 2 : Using self join
delete from students where id in
(select s2.id from students s1 join
students s2 on s1.name=s2.name and
s1.age=s2.age where s1.id<s2.id )
Sol 3 : Using min function. It will remove multiple duplicates
delete from students where id not in(
select min(id) from students
group by name,age )
Sol 4 : Using window function ( row_number() )
delete from students where id in
(select id from
(select *, row_number()
over(partition by name,age) as rn from students)
where rn>1)
Here is the detailed post where row_number() explained, you can have a look.
Sol 5 : Using backup table
create table stu
as
select * from students where 1=2 --< table creation
insert into stu
select min(id) from students
group by name,age --< Data insertion
drop table students --< Drooping old table
alter table stu
rename to students --< Renaming new table in as old table name
Sol 6 : Using backup table without dropping original table
create table stu
as
select * from students where 1=2 --< table creation
insert into stu
select min(id) from students
group by name,age --< Data insertion
truncate table students --< Deleting data from old table
insert into students
select * from students --< Inserting data to old table from backup table
Scenario 2 :
Where the whole row is duplicated including id column.
Sol 1 : Using CTID ( ROWID in Oracle SQL )
delete from students
where ctid not in(
select min(ctid) from students
group by name,age)
Sol 2 : By adding a temporary column in current column
alter table students add column
row_num int generated always as identity --< Adding new column
delete from students where
row_num not in(
select min(row_num) from students
group by name,age) --< Removing duplicates
alter table students drop column row_num --< Dropping newly added column
Sol 3 : Using backup table
create table stu
as
select * from students where 1=2 --< Creating backup table
insert into stu
select distinct * from students --< Inserting unique record to new table
drop table students --< Dropping old table
alter table stu rename to students --< Renaming new table
Sol 4 : Using backup table without dropping original table
create table stuu as
select distinct * from students --< Creating backup table
truncate table students --< Deleting rows of old table
insert into students
select * from stuu --< inserting data to old table from backup table
The youtube video explaining the 10 ways to remove duplicates in SQL in hindi
In this video I have explained in detail ” How to remove duplicates in SQL in hindi
Frequently Asked Questions :
How to delete all duplicate record except one record from the table?
Above shown through each & every method you can delete all duplicates except one record which is your base or original record.
How to remove duplicate data in Productions?
In production environment you can’t remove duplicates as I have shown ” Using Backup table ” because, in this method you have to drop the existing table but in production environment if you drop the original table then your application on which you are working it will get crushed.